トム・フォーリーが語る、レコメンドエンジンに必要な技術とポリシー
シルバーエッグ・テクノロジー株式会社
代表取締役社長 & CEO
トーマス・アクイナス・フォーリー
当社はAI技術を基軸としたレコメンドサービスを20年に渡り提供しています。その根幹にあるのは、ユーザー個人レベルでの嗜好・ニーズ分析に基づくパーソナライゼーションの実現です。このブログでは、我々の製品が具体的にどのような技術に立脚しているのか、また、なぜその技術を選んだのかを説明したいと思います。
【INDEX】
・進化するレコメンド手法「協調フィルタリング」
・なぜ「行動情報」と「協調フィルタリング」か?
・顧客の個人情報を守り、尊重する
・レコメンドはユーザーの選択を尊重するものでなければならない
・レコメンドで消費者を“うんざり”させないための努力
進化するレコメンド手法「協調フィルタリング」
優れたレコメンデーション・システムは、ユーザー1人ひとりのレベルで、「何を好むか」「何を求めているか」を、その人が実物を見る前に予測することができます。この予測は、ユーザーがどのように行動するかを分析し、人とモノとの潜在的な関連性を発見することで実現します。例えばNetflixの場合、ある韓流の恋愛ドラマを好きな複数の視聴者が、別のあるドラマも好きであると分かれば、確信を持ってそのドラマをまだ観たことがない視聴者に薦めることができます。
このように、アイテムをレコメンドするために、ユーザーの行動の類似性を活用する手法を総称して「協調フィルタリング」と呼びます。この手法のコンセプトは古くから知られていますが、未だ活発な研究開発が行われおり、マーケターが利用できる予測手段としては、現時点で最も強力な手法です。
ディープラーニングをはじめ多くの最新テクノロジーを援用し、協調フィルタリングの予測精度や活用度を向上しようという試みは、様々な研究でなされてきました。どのような要素技術を使ったソリューションが役立つかは、レコメンドの用途によって異なります。シルバーエッグは、オンライン上での「行動分析」と、AIによる「自然言語処理モデリング」との共通点に着目し、独創的なレコメンドソリューションを多数考案してきました。
翻訳などに使われる自然言語処理モデリングに、レコメンドエンジンと似た部分があるというのは、意外に思われるかもしれません。実は、顧客がアイテムを選択する順番の分析手法と、会話や文章における言葉の語順の分析手法には、多くの共通性があるのです。AI技術で多くのテキストを分析し、文章がどのように完結するかを予想できるのであれば、同様に多くのショッピング・セッションを分析することで、顧客の好みそうなアイテムを予想することも可能なのです。
なぜ「行動情報」と「協調フィルタリング」か?
アイテムに関する個々の顧客の好みの類似性に基づいてレコメンデーションを生成する「協調フィルタリング」は、先に書いたように、20年以上前から知られているコンセプトです。好みやニーズを分析するために利用する「行動情報」には、商品評価や「いいね」のようなユーザーが明示的に表明するものもあれば、閲覧行動や購買行動の変化を通じて暗示的に得られるものもあります。
もちろん、行動情報以外のリソースで、ユーザーの好みを予想する方法もあります。それらの方法は有効ではないのでしょうか? 少し考えてみましょう。
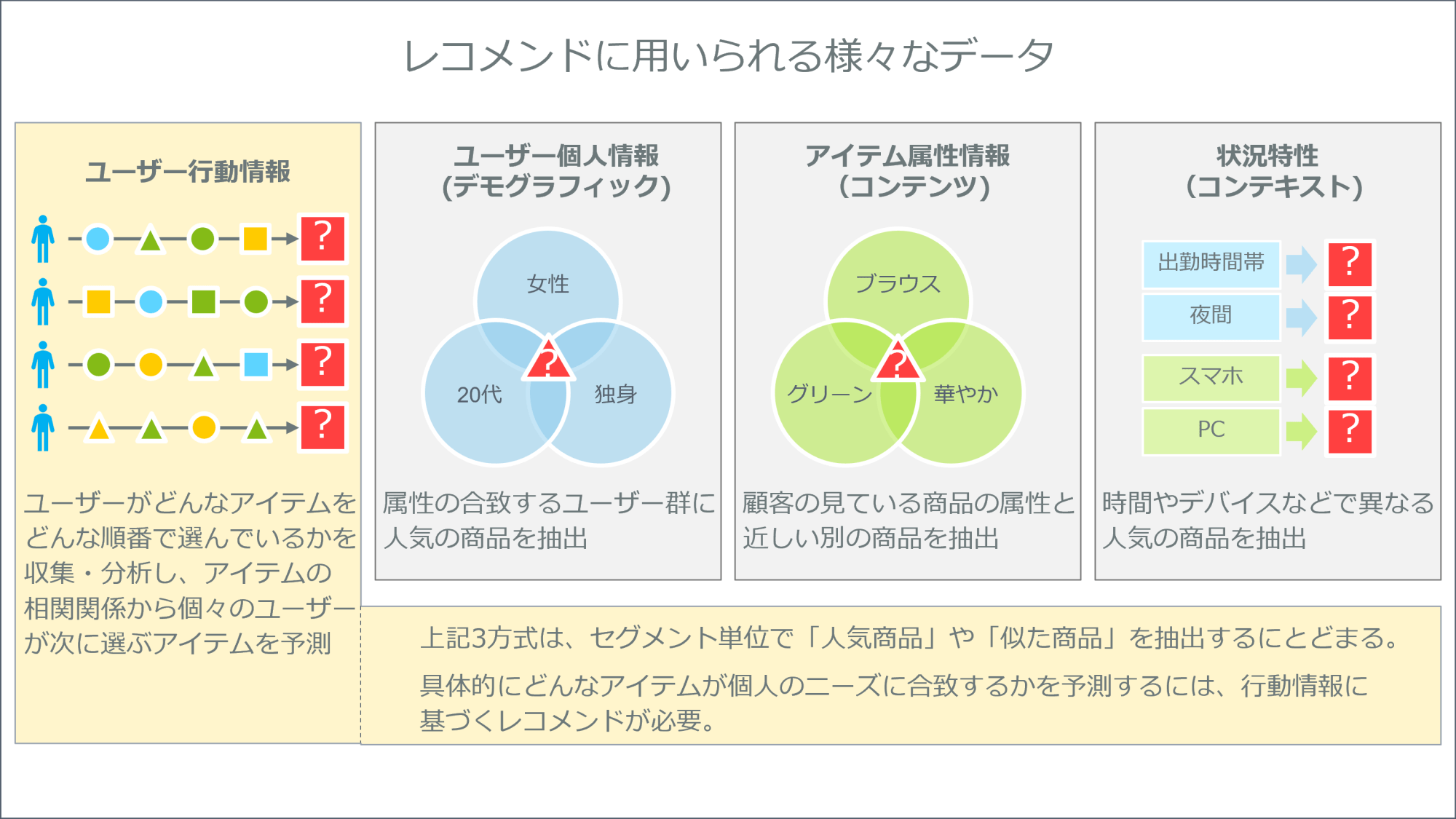
ユーザー個人情報:デモグラフィックに基づくレコメンド
年齢や性別など、登録フォームなどからユーザー個人の属性情報を収集できれば、人口統計上のある一定の集団が、特定のアイテムやコンテンツを好むことを発見できるでしょう。このようなデータを使ったやりかたは、インターネット時代以前のマーケティングの主流でした。
アイテム属性情報:コンテンツベース・レコメンデーション
テキストのクラスタリング、画像認識、ユーザーが作成したラベル(ハッシュタグなど)によって発見されるアイテム(またはコンテンツ)群を使用するレコメンデーションです。
状況的特性:コンテキスト・ターゲティング
レコメンドを行うコンテキスト(状況)を活用します。例えば、1日の中でいつ行うか、どこで行うか、どのような環境で行うかなどです。
これらの情報の利用については、単純ですが本質的課題があります。ユーザー個人情報、アイテム属性情報、状況的特性のいずれについても、それらが、顧客のアイテムの好みとどう相関するのかを検証しないかぎり、レコメンデーションを行うことはできないのです。
結局、こういった多様な情報を活用するためにも、協調フィルタリングによる強力な予測技術が必要なのです。言い換えれば、これらの情報の活用や様々な新技術を謳うレコメンドエンジンも、実際のところ協調フィルタリング型エンジンの変異種にすぎないと言えます。
真に重要なのは予測力です。AI技術によるパーソナライゼーションが重要な理由はそこにあります。手持ちの材料が人口統計データやアイテムの種類だけでは、予測力は失われます。集団が大きくなるほど、レコメンデーションの重要性は薄まります。
個人レベルの分析を諦め、ざっくりした“顧客群”に対してレコメンドをしても、できることは人気アイテムを薦めることくらいです。でもそれは決して、真の顧客満足やロイヤリティを生むことはありません。
顧客の個人情報を守り、尊重する
AIはパターンを発見します。協調フィルタリングではそれを利用して、ユーザーの行動がアイテムの好みにどう関係しているかを発見します。「ユーザーの行動」というと、個人に紐づくセンシティブなものだと考えられますが、AI分析に必要なのは「誰が」行動したかという直接的な個人情報ではなく、数値化された行動の統計情報です。このデータの塊は、データサイエンティストでさえ解釈するのは困難ですし、ハッカーが欲しがるようなデータではありません。
実際、シルバーエッグの「アイジェント」サービスでは、AIがレコメンドの計算を行うにあたり、ユーザーの匿名性は維持されます。誰が誰であるかを知る必要はないし、誰であっても構わないからです。
とはいえ、消費者はオンライン上での行動がどのように監視され、利用されているかに警戒すべきというのは、まったくその通りだと思います。どのサイトもひそかにそれをやっています。大手の検索エンジンやSNSは、あなたについて、お気に入りのショッピングサイトよりも、はるかにさまざまなことを積極的に追跡し、人物像を構築していると思って間違いないでしょう。
顧客についてのナレッジを企業が扱うにあたり、重要なのは信頼と価値の好循環があるかどうかだと私は考えます。インターネットは私達にこれまでにないほどの選択肢をもたらしました。企業はパーソナライズされた高価値なサービスを競って提供しています。しかし、顧客に寄り添ったサービスを実現するためには、顧客ナレッジを深める必要があり、顧客を知るには、顧客の信頼を獲得する必要があります。
最終的には、どのサイトやサービスが信頼に値するか、自分が受け取っている価値が信頼を授けるに足るものかを判断するのは消費者です。シルバーエッグは、その点をはっきりと認識しています。企業に対し、競合力のあるパーソナライズされた付加価値サービスを提供できるようにするため、当社は必要な信頼を得られるように常に努力する必要があります。責任を持って消費者のデータを保護し、利用しないとすれば、それは愚かな自滅行為です。
レコメンドはユーザーの選択を尊重するものでなければならない
「顧客に商品を勧める」という意味で、さまざまなウェブサイトで表示される「リターゲティング広告」は、時に協調フィルタリングによるレコメンド表示と混同されることがあります。リターゲティング広告を見て、自分の行動が監視されていると不快に感じる人もいるでしょう。
実際、リターゲティング広告と協調フィルタリングによるレコメンドとは、原理も目的もかなり異なります。最も基本的なタイプのリターゲティングでは、以前に閲覧したか、カゴ落ちして購入しなかったアイテムの広告が表示されます。過去にユーザーがそのアイテムを欲しがっていたので、リマインドすれば買うかもしれないというシンプルな前提に立った広告技術なのです。
リターゲティング広告は複数のサイトを通じて消費者を追跡する必要もあるため、プライバシーや信頼の管理がはるかに問題になります。リターゲティングは必ずしも悪いものではないのに、実際は多くがそうなってしまっていると感じます。典型的な例は、「レコメンド」の行為全体が、誤った方向に向かいかねないことです。例えば、何らかの理由で買う選択をしなかった商品について、しつこくリマインダーを送られるのは気味が悪いでしょう。
そのように考えると、リターゲティングは購入を先送りした消費者の選択を尊重していません。決断を再考させようと消費者をしつこく追い回しています。客の買い控えを、事情に配慮することもなく、収益化しようとしているのです。これではレコメンデーションが完全な悪者になってしまいます。
レコメンデーションは、消費者の意志に反して、あるいは経済力を超えて、購入を促すべきではありません。レコメンデーションとは、ほかの選択肢を発見できるように、あるいはより多くの情報に基づいてより良い選択を下せるように、人々を助けることです。それはセレンディピティであり、消費者にとっては発見や表現であるべきで、無理強いであってはなりません。
レコメンドで消費者を“うんざり”させないための努力
サイトの「あなたへのおすすめ」欄に、いつも似たような商品ばかり表示されるため、消費者の中にはレコメンドエンジンをうっとうしいと感じているも方もいらっしゃると思います。業界最先端と言われる技術を用いたNetflixのおすすめでさえ、時にはそう言われています。ユーザーの“うんざり”は、どうやって解消すればいいのでしょうか? それは並大抵なことではありません。
例えばもし、ユーザー自身がレコメンドエンジンを調整することができて、カスタマイズしたカタログを自身で探索できるようになれば、すばらしいと思いませんか? そうしたより双方向的なレコメンデーションが近い将来にみられるようになるかもしれません。もちろん私達もそれについて検討中ですが、ここではレコメンドが繰り返し何度も表示される問題についてお話しさせてください。
これは、とても本質的な問題です。協調フィルタリングの基礎の一つともいえる、アソシエーション分析による初歩的なレコメンドは、アイテムの単純な相関性に基づいています。映画「X」を観た人々の多くは、映画「Y」も観るといったようにです。そこで、Xを観たばかりの視聴者には、常にYがおすすめに表示されることになります。
初歩的なレコメンドエンジンは、視聴者がそのおすすめを何回見せられたか、そして何回それに反応しなかったかを考慮しません。実際、視聴者はすでにその映画をどこかで観ているかもしれません。同じレコメンドの連発を避け、何か別のことを試すような仕組みが求められます。
また、現在使われているレコメンドエンジンの多くは、静的なデータ、つまりある時点で取得した行動データを分析し、相関性を発見します。データを取得したのが1週間前であれば、その後7日にわたって、同じレコメンドを長期間出し続けることになります。
これらの問題を防ぐためには、リアルタイムで、各ユーザーから学習し反応するレコメンドエンジンが必要です。例えば、ECサイトで何かを購入し、その製品以外に興味が移ったことを、即座に行動から学ぶような仕組みです。
もう1つの問題があります。レコメンデーションに効果があれば、そこにはフィードバックループが生まれます。顧客がおすすめに従うことで、ネット閲覧と購入の弱い相関性が強化され、結果的に同一アイテムが提案される頻度が増加します。その結果、ロングテールアイテム(売れ筋以外のニッチなアイテム)を排除するバイアスが次第に増していく「エコーチャンバー」という現象が生じます。しかし、本当に顧客に発見してもらいたいのは、ロングテールアイテムなのです。
ここで押さえておくべきは、レコメンデーションを行う企業は多くあれど、真に顧客を満足させ、オンラインビジネスの可能性を最大化するレコメンドは並大抵ではないということです。シルバーエッグは、この技術のエキスパートとでありたいと尽力しています。私たちは既にいくつかの問題に対する解決策を考案し、システムに実装してきました。今後もより高度な技法で、顧客を満足させるサービスの開発を続けていきます。
