VLMとは?従来の画像認識との違いとECのコールドスタートを解決する「V-レコ」の仕組み

「データのない新規顧客」や「入荷したばかりの新商品」へのレコメンドがうまく機能せず、コールドスタートによる機会損失を生んでいませんか?
この記事では、従来の行動データだけに頼るのではなく、商品の“見た目”や“雰囲気”を判断する最先端AI技術「VLM(視覚言語モデル)」の基本を解説します。
さらに、VLM搭載の次世代画像レコメンドの仕組みとメリット、導入や売上向上の方法、効果についてもまとめています。
【この記事の内容】
- VLM(視覚言語モデル)とは?LLMとの違いとECにおける活用
- VLMの学習方法と従来の画像認識との違い
- VLMが実現する画像レコメンドのメリットと実用例
- 次世代画像レコメンドサービス「V-レコ」
- まとめ

VLM(視覚言語モデル)とは?LLMとの違いとECにおける活用
VLM(Vision-Language Model)とは
VLM(視覚言語モデル)とは、画像や動画などの視覚情報と、テキストなどの言語情報を組み合わせて理解・生成できるAIモデルのことです。
従来のAIはテキストのみ、あるいは画像認識のみという単一のデータ形式(モーダル)を扱うのが主流でしたが、VLMは「画像の内容を言葉で説明する」「言葉による指示で画像を編集する」といった、領域を横断した高度な処理を可能にします。
VLMとLLMの違い
テキストの文脈理解や生成に特化したLLM(大規模言語モデル)に対して、VLM(視覚言語モデル)は、その言語能力に視覚を組み合わせたものです。
LLMが文字のみを扱うのに対し、VLMは画像や動画を直接「見て」理解できます。
LLMは膨大なテキストデータから学習した、自然言語処理に特化したモデルです。テキスト情報に対して、自然な会話、長文の作成・要約、論理的な推論といった情報をテキストで返すことができます。
これに対してVLMは、テキストと画像を結びつけてマルチモーダルに思考することができます。グラフの解析のように画像の内容を説明したり、写真の中の文字を読み取ることもできます。これによりVLMは製品の異常検知や医療画像診断、自動運転の状況判断に応用されています。
ECサイトでは、LLMは商品説明からタグを生成したりAIチャットボットによるカスタマーサポートに利用されています。VLMは、商品画像から色や形を自動判別し、タグ付けやレコメンドを行うのに利用されます。
VLMの学習方法と従来の画像認識との違い
VLMは従来の画像認識モデルとも、学習するデータや学習方法が異なります。従来の画像認識では、学習のために暗記する画像-テキスト(単語)のセットを用意しなければならないのに対し、VLMはWeb上などの画像-テキスト(文)を自律的に学習します。
このため、VLMは学習のためのデータを人間が用意せずとも、膨大なデータを学習することができます。
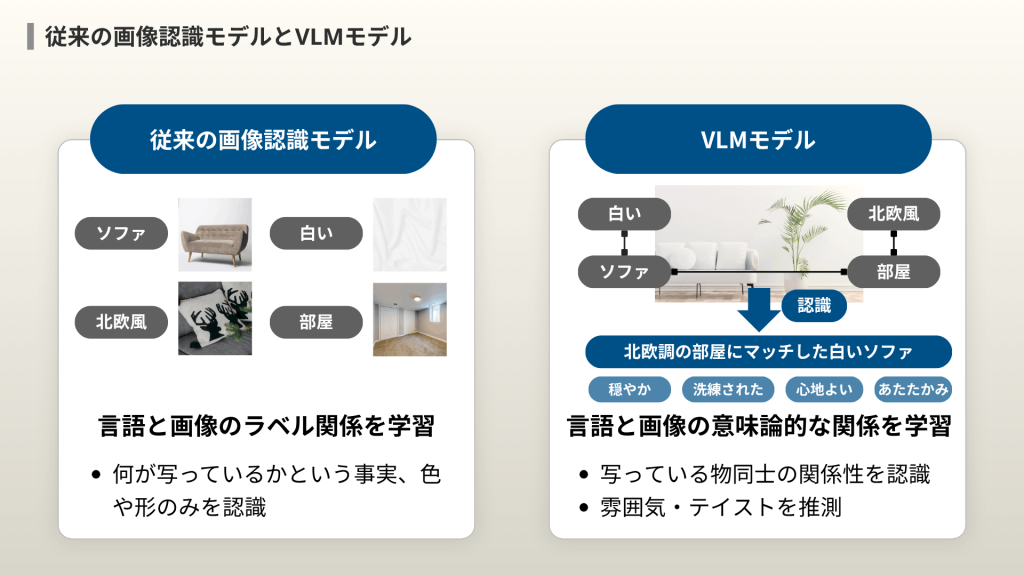
従来の画像認識は、単純な個々の語(「北欧調」「白い」「ソファ」)とそれに対応する画像とのラベル関係を学習しました。
これに対してVLMは、句や文(「北欧調の部屋にマッチした白いソファ」)とそれに対応した画像から、語と語の関係性を学習するため、文脈や概念同士の意味論的なつながりを認識することができます。
さらに、単に「何が写っているか」という事実だけでなく、画像全体の「雰囲気やテイスト」まで推測できるのがVLMの大きな強みです。
従来の画像認識では、新しい概念や言葉を認識させるために、大量の画像を集めて再学習をやり直す必要がありました。
しかしVLMは、言葉と画像のつながりを根本から理解しているため、事前の専用学習なしで新しい言葉や未知のイメージを処理することができます。この驚異的な能力は、AIの世界でゼロショット能力と呼ばれています。
| 項目 | 従来の画像認識モデル | VLMモデル |
|---|---|---|
| 教えるデータ | 画像 + 人間が作った正解ラベル | 画像 + 日常で使われる説明文 |
| 人間の作業工数 | 膨大(1枚ずつタグ付けが必要) | ほぼ不要(既存の商品画像と説明文でOK) |
| AIが覚えること | A=B という単純な「分類」 | 画像と言葉の「意味的なつながり」 |
| 新しいトレンド | 再学習しないと認識できない | ゼロショット 教えていなくても言葉の文脈で推測できる |
VLMが実現する画像レコメンドのメリットと実用例
従来の画像認識モデルから大きく進化したVLMの登場により、画像レコメンドも飛躍的に進化しました。
VLM画像レコメンドのメリット
従来の画像レコメンドは、あくまで「画像データのパターンマッチング」であり、ラベルと光学的な要素のみから類似性を分析します。
そのため、次のような弱点がありました。
従来的な画像レコメンドの欠点
- 言葉のニュアンスが汲めない
「形は似ているけれど、もっとフォーマルな場に合うもの」といった、TPOや文脈を踏まえた推薦は苦手です。 - 背景に惑わされる
商品写真の背景(モデルのロケ地やスタジオの小物)が似ているだけで「類似品」と判定してしまうエラーが起きることがあります。
VLMを活用したレコメンドのメリット
- 無限の語彙
学習していない新しいトレンドワード(例:「地雷系」「平成レトロ」)なども、文脈から判断してタグ付けできる。 - 情緒的表現
「雨の日に似合う」「ビンテージ風の質感」といった、感性に訴えるタグを自動で生成できる。
VLMはゼロショット能力をレコメンドや検索に応用することで、ユーザーの脳内イメージに合致する商品を、取りこぼすことなく的確に提案・検索できるようになります。
VLMは人間のように概念やニュアンスとして捉え、ECのレコメンドや検索において、ユーザーの感性に直接響くアプローチを可能にします。
VLMレコメンドの実用例
VLMをレコメンドに応用することは非常に強力なアプローチであるといえますが、高度な計算が必要なため、リアルタイムで大量の商品を処理するにはコストがかかるという課題があります。また初期には自由度の高さから間違った(あるいは余計な)レコメンドをしてしまう傾向もありました。
しかし、2026年現在ではファッションやインテリア業界、大手プラットフォームといった先進的なサイトでは、先行して実用化されています。具体的な実用例をご紹介します。
- 大手リユースプラットフォーム:視覚的類似度によるレコメンド精度の改善*
VLMの一種であるSigLIPを活用し、商品画像とテキスト(商品説明)の両方を統合して理解する仕組みを導入しています。これにより商品名だけでは表現しきれない「柄」や「色味」「シルエット」の微細な違いを検索やレコメンドに反映し、「見た目が近い商品」の精度を大幅に向上させました。 - 大手マーケットプレイス:ドメイン特化型VLMによる商品属性抽出**
自社のマーケットプレイスにおいて、ファッション分野のVLM活用を推進しています。商品画像から「襟の形」「生地の質感」「丈感」などの詳細な属性(メタデータ)をAIが自動抽出し、これをレコメンドエンジンに供給する手法を構築しています。
次世代画像レコメンドサービス「V-レコ」
V-レコが選ばれる理由:高精度なVLMエンジンとEC特化の解析ロジック
V-レコはVLMモデルを搭載した最新の画像レコメンドです。通常のAIレコメンドと掛け合わせることで、ユーザーの購買行動をさらに活性化させることができます。
インターネット上の膨大な「画像と関連するテキスト」のデータを事前に学習しており、新商品やトレンドにゼロショットで対応することができます。

従来の一般的な画像レコメンドと異なり、V-レコは商品の色・形だけでなく、その画像が持つ「意味や潜在的な概念の近さ」までを深く分析・理解して類似商品を即座に検出します。これにより、個別チューニングの手間をかけることなく、幅広いジャンルの商品画像において一貫した高精度を発揮します。
また、EC運営において極めて強力なのが、リアルタイムレコメンドサービス「アイジェント・レコメンダー」との連携を前提としたEC特化の解析ロジックです。
ユーザーの閲覧や購買行動をリアルタイムに追う「行動情報分析AI」と、商品のビジュアル的な特徴を捉えるV-レコのVLMを相互補完的に組み合わせることで、従来のレコメンドエンジンが必ず直面していた「コールドスタート問題(データが不足する新規ユーザーや新商品への推薦が難しくなる課題)」を高いレベルで緩和します。
V-レコ導入で期待できる効果
V-レコをサイトに導入することで、オンラインビジネスの成長に直結する以下の3つの効果が期待できます。
初回訪問ユーザーの購入促進とリピート化
過去の行動データが存在しないためニーズ予測が難しい初回訪問ユーザーに対し、いま見ている商品に類似した「概念の近い商品」をいち早く的確にレコメンド枠に提示します。ユーザーの「欲しい商品が見つけづらい」というストレスを解消し、心地よいレコメンドを体験してもらうことで、離脱を防ぎリピートユーザー化を強力に支援します。
「新商品」や「ロングテール商品」の販売促進
サイトに登録されたばかりの新商品や、まだ誰にも閲覧されていないロングテール商品は、行動情報ベースのレコメンド枠には掲載されにくいという弱点がありました。
V-レコは、画像さえあれば形状、色・模様、ジャンル、用途といった多様なビジュアル特徴から他の商品との類似性を即座にマッピングします。
閲覧数の多い人気商品のページなどにも関連商品として積極的に露出(認知度改善)させることができるため、新商品の初動を早め、埋もれていた商品の探索を活性化させます。
手動運用の完全自動化によるコスト・運用工数の削減
アイジェント・レコメンダーの商品データベースと自動で連携して解析を行うため、導入後にサイト管理者が商品ごとに個別の設定を行ったり、都度アルゴリズムのチューニングをしたりする運用作業は原則不要です。SKU(商品数)が膨大な大規模ECサイトであっても、運用の人件費や手間を増やすことなく、常に最新のカタログ状況に応じた自動レコメンドが維持されます。
V-レコの導入と既存システムとの連携プロセス
最先端のAI技術でありながら、サイト担当者の導入・実装負荷や開発コストを極限まで抑えたスムーズな連携プロセスが構築されています。
自動的な商品データ(アイテムマスター)連携
アイジェント・レコメンダーが既存のECシステムと連携して自動的に収集している商品画像データをそのままV-レコの画像解析AIへ供給します。
新商品の追加やデータのアップデート処理、それに伴う類似商品解析は定期的にバックグラウンドで自動実行されます(データの取り込み頻度は日次をベースにお客様側で任意に設定可能です)。そのため、現場の担当者がシステムへ画像を都度アップロードするような二度手間は発生しません。
アイジェント用のHTMLタグを挿入するだけの簡単実装
自社サイトの画面上にV-レコのレコメンド枠を表示させるための作業は、既存のアイジェント用HTMLタグを挿入するだけで完了します。枠を設置するために個別の複雑なシステム開発を行う必要はなく、自社サイトのデザインやレイアウト、ブランドのトーン&マナーに合わせて表示位置を柔軟に調整することが可能です。
多様なアルゴリズムとのハイブリッド運用
V-レコによる画像解析アルゴリズムだけに依存するのではなく、アイジェント・レコメンダーが本来持つ多彩なレコメンドアルゴリズム(リアルタイムの行動情報分析など)と柔軟に組み合わせて表示設定を行うことができます。自社サイトの顧客属性やビジネスモデルに最もマッチした最適なレコメンド表示をノンストレスで実現できます。
まとめ
本記事では、次世代のAI技術VLMの仕組みと、それをレコメンドへ応用した「V-レコ」がもたらすビジネスの変革について解説してきました。
従来のレコメンドが数字(統計データ)や限られたテキストタグに依存していたのに対し、V-レコはLLMの技術を応用し、商品の見た目や潜在的な概念を直接ロジックに組み込みます。これにより、これまで予測が難しかった「初回訪問ユーザー」への的確な提案が可能になり、「新商品やロングテール商品」の埋没を防ぐことができるようになります。
アイジェント・レコメンダーとの自動連携により、現場の運用工数やシステム構築の手間を増やすことなく完全自動化できる点は、リソースに限りのあるサイト担当者やCRM担当者にとっても極めて大きなメリットです。
消費者の「言葉にできない“なんとなく好き”」を視覚データから紐解き、購買へと繋げるV-レコ。競合他社との差別化や、データ不足による機会損失の解消を目指す事業者様は、視覚データを武器にした次世代のパーソナライズ戦略を検討してみてはいかがでしょうか。
VLM搭載画像分析レコメンドサービス
Referrence
* メルカリ: Vision-Language Modelを活用した「見た目が近い商品」レコメンド改善の取り組み
https://engineering.mercari.com/blog/entry/20241104-similar-looks-recommendation-via-vision-language-model/
** AWS Blogs: Fine-tune VLMs for multipage document-to-JSON with SageMaker AI and SWIFT
https://aws.amazon.com/jp/blogs/machine-learning/fine-tune-vlms-for-multipage-document-to-json-with-sagemaker-ai-and-swift/
