進化の歴史でわかるレコメンドエンジン。アルゴリズムの分岐と「協調フィルタリング」
自分たちのサービスに合った、成果を出しやすいレコメンドエンジンは何だろう? そんな質問が多く寄せられています。
レコメンドエンジン開発の歴史を振り返ることで、機能や性能の違いを知ることができます。

お気に入りのショッピングサイトを訪れると、「あなたにおすすめの商品」が表示されるのは、今では当たり前のことになっています。
しかし、現在のようにユーザーに合わせた高度なパーソナライゼーションが可能になるまでに、レコメンドシステムは多様な分岐と進化を遂げてきました。
その結果、ひとことで「レコメンドエンジン」と言っても、その機能や性能もさまざまなものとなりました。
では、どんなレコメンドエンジンならば、自社のサイトに最適な効果を発揮できるのでしょう?
この記事では、レコメンドエンジンの進化において重要な、以下のブレイクスルーに着目して、レコメンドエンジンの進化を振り返っていきます。
【INDEX】
・ レコメンドエンジンの始まりとコンテンツベースのレコメンド
・ 「協調フィルタリング」とは? Amazon と Netflix のインパクト
・ 協調フィルタリングの分岐とハイブリッド
・ どんなレコメンドがよい?レコメンドエンジン導入時に気を付けること
・ まとめ
レコメンドエンジンの始まりとコンテンツベースのレコメンド
インターネットの黎明期には、実用的なパーソナライゼーションの手法はほとんどありませんでした。そのため、「何かを見つけたい」というユーザーのニーズに対しては、検索エンジンがその解決策の役割を一手に担っていました。
初期のレコメンドサービスでは、検索されたキーワードに紐づく複数のアイテムを並べて表示するといった工夫をしていました。
さらに、ユーザーの購入履歴を利用し、過去に購入した商品があれば、それに関連する商品
をおすすめするという手法を取っていました。
このような手法では、たとえば、あるブランドの製品を購入したことがあれば、そのユーザーはそのブランドを好んでいると解釈され、将来的に同じブランドの製品を購入する可能性があるという推測に基づき、おすすめをします。
このように、個々のユーザーの検索や購買の履歴に基づいて、関連する商品を推薦するレコメンドシステムは、「コンテンツベース」のレコメンドシステムと呼ばれています。
しかしコンテンツベースのレコメンドには、いくつかのデメリットがあります。
〈コンテンツベースの特長〉
・ 時間の経過によるユーザーの関心事の移り変わりには対応できない
・ 最適なレコメンドを行うには、ユーザーとその嗜好に関する多くの履歴データが蓄積されていなければならない
・ すでに入手できない商品を推薦してしまう可能性がある
たとえば、ユーザーがある作家の小説を購入したからといって、コンテンツベースの手法で同じ作家の別作品をおすすめして良いのでしょうか? ユーザーが小説を読み、その内容を退屈だと感じていれば、同じ作家の作品を購入する可能性は非常に低くなります。また、ユーザーが内容を気に入っていたとしても、同じ作家の絶版作品をレコメンドしては意味がありません。似た作風の作家の新刊をレコメンドした方が、次の購入につながる可能性があります。
「協調フィルタリング」とは?Amazon と Netflix のインパクト
1990年代後半、Amazon.com(*) は「協調フィルタリング」に基づく新しい種類のレコメンドシステムを開発し、提供を開始しました。
「協調フィルタリング」(Collaborative Filtering)のレコメンドシステムは、 「コンテンツベース」のレコメンドシステムの欠点を補い、パーソナライゼーションを一歩前進させました。
協調フィルタリングのレコメンドでは、その名の通り、ユーザー個人でなく、ユーザーグループの行動を利用して、他のユーザーにおすすめを行います。
これにより、コンテンツベースのレコメンドによるデメリットのいくらかが解決されました。グループの行動履歴は、個人の行動履歴よりも情報の蓄積速度が速く量も充実しやすいからです。そのためユーザーの関心事や商品の情報も比較的速いペースで更新され、時間経過による関心の移り変わりや在庫の喪失といった問題はいくらか解決されました。
その後Amazonは高い競争力によって、瞬く間にオンライン市場を席捲していきました。以来、協調フィルタリングに基づくレコメンドは、多くのECサイトで実装されることとなりました。
そして、2000年代にはもう1社、レコメンデーション技術を持つ有力な企業が登場します。Netflix(*)です。
2006年当時、Netflixは映画のDVDを郵送して貸し出すというビジネスを行っており、レンタルされる機会の少ないアイテムをもっと多くのユーザーが借りるようになれば、大規模な収益向上が実現できると考えました。
Netflix は、このいわゆる「ロングテール」のビジネスモデルを促進する鍵になるのが、レコメンドシステムだと考えました。
Netflixは自社のレコメンドシステムの精度を10%向上させたアルゴリズムを開発したチームに100万ドル の賞金を与えるというコンテストを開始し、2009年には、ついに優勝チームが発表されました。
周知の通り Netflix はその後動画配信サイトに進化しました。ビジネス形態は変わりましたが、レコメンド技術はなおも重要な成果を担い続けています。
協調フィルタリングの分岐とハイブリッド
2000年代にめざましい発展をとげた協調フィルタリングベースのレコメンドですが、ここで分岐を整理しておきましょう。
協調フィルタリングには、メモリベースとモデルベースの2種類があります。
メモリベース
メモリベースの特徴を要約すると、単純で処理回数の多いレコメンドと言うことができます。
〈メモリベースの特長〉
・ ローデータを処理する単純なレコメンド
・ 毎回、すべてのデータに対して予測を行う必要があるため、速度が遅い
メモリベースはさらに、ユーザーベースとアイテムベースの2種類のアプローチがあります。
ユーザーベース: 「あなたに似たユーザーは、……も好きです」似たユーザーの傾向をもとに、特定のユーザーが好むと思われるアイテムをおすすめします
アイテムベース: 「このアイテムを気に入ったユーザーは、……も好きです」同じアイテムを購入/評価したユーザーが好む別のアイテムをおすすめします
ユーザーベースのアプローチとアイテムベースのアプローチを比較すると、アイテム間の類似性はユーザー間の類似性よりも固定的であるため、安定したレコメンドをすることができます。また通常、アイテムの多様性はユーザー嗜好の多様性より少ないことが多いため、処理しやすいという利点もあります。
しかしユーザーの関心や嗜好は常に移り変わります。先週好きだったものは、来週は好きではないかもしれません。トレンドの移り変わりの早い商品などにはユーザーベースの方が効果を発揮する場合もあります。
モデルベース
モデルベースは、機械学習アルゴリズムを使用して開発されました。
モデルベースの特長は、あらかじめモデルを作成しておき、それに基づきレコメンドアイテムを提示するということです。
このため、メモリベースよりも処理が早く、スケーラビリティも高いという利点があります。
このアプローチの最も有名なタイプは、行列分解(Matrix factorization)です。先に紹介した Netflix の優勝者のアプローチもこれに該当します。行列分解では、ユーザーの特徴とアイテムの特徴をそれぞれ抽出し、そのデータに基づきレコメンドをするため、処理が早くスケーラブルという特長があります。
ハイブリッド
さらに、さまざまなレコメンドシステムを組み合わせた、ハイブリッドなレコメンドエンジンがあります。
ハイブリッド型のレコメンドエンジンでは、異なるアプローチのレコメンドを組み合わせることで、特定のアプローチによるレコメンドの欠点を補うことができます。このため単一のアルゴリズムよりも、より最適なレコメンドをすることができます。
どんなレコメンドがよい?レコメンドエンジン導入時に気を付けること
いかがでしたでしょうか。レコメンドエンジンの開発の歴史を振り返りながら、その多様なアプローチとそれぞれの長所と短所、性能の違いが理解できたのではないでしょうか。
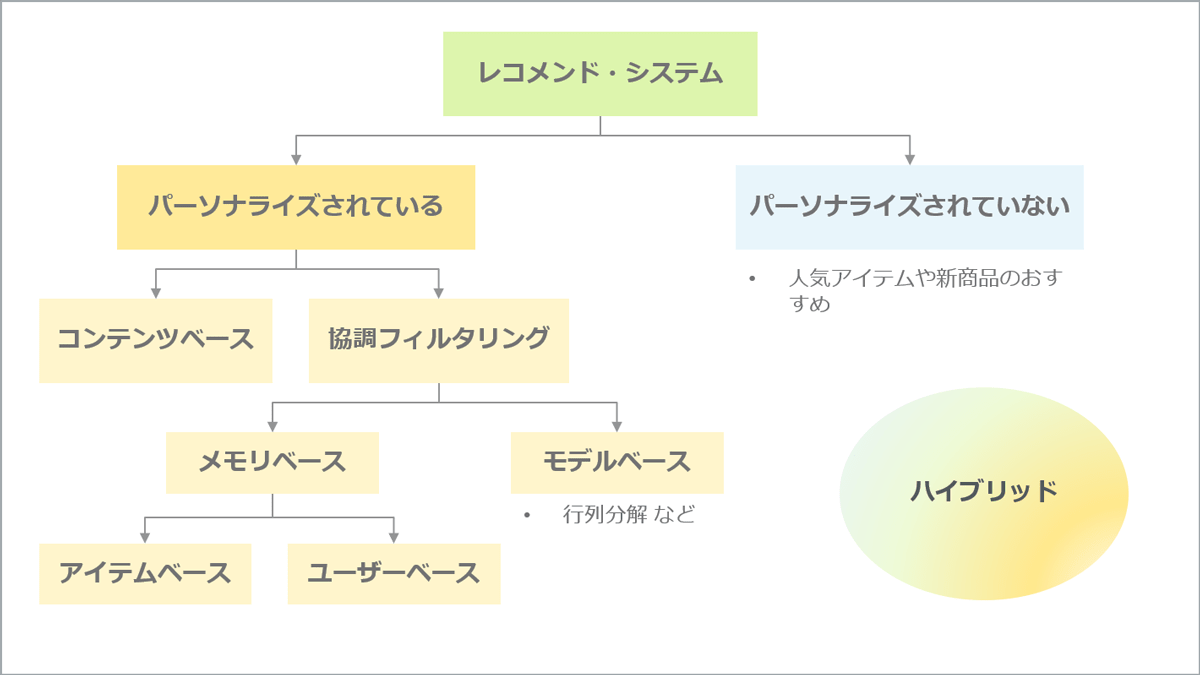
レコメンドシステムの分岐
こうした知識は、実際にどのレコメンドエンジンが良いかを検討するとき、一つの指標となります。
どのレコメンドエンジンが自社のサイトに最適かは、解決されるべきビジネス上の課題によって異なります。
たとえば時間の経過によるトレンドの変化にほとんど影響を受けず、ロングテールに光を当てたいというサイトもあるでしょう。また、反対にファッションのようにユーザーの関心や流行が移ろいやすい商材もあるでしょう。
いくら性能の良いレコメンドであっても、その機能が必要のないサイトや商材であれば意味がありません。
近年の分析では、Amazonでは35%以上、Netflixでは60%以上がレコメンドにより、ユーザーが購入/視聴に至ったという結果が出ています(**)。
初期よりレコメンドへの投資を注いできたこの2つの企業が示す数字は驚くべきものです。
しかし、この数字は単純にレコメンドエンジンの性能の高さをだけを表しているわけではありません。両社が、自社のユーザーのニーズを満たすのに最適なレコメンドエンジンをビジネスの中核に置いていることの表れでもあります。
先に紹介した Netflix のコンペで優勝したレコメンドシステムは、実際には使用されませんでした。 顧客のニーズを十分に満たしていないと判断されたからです。
どのレコメンドエンジンが良いのか?重要なことは、自社の課題が何であり、それを解決してくれるのはどういったレコメンドなのか、戦略的な判断をすることです。
まとめ
・ インターネットの黎明期に、コンテンツベースのごく単純なレコメンドが登場した
・ 1990年代から2000年代には、協調フィルタリングのレコメンドにより、処理速度や精度が劇的に改善された
・ 協調フィルタリングには、メモリベースとモデルベースの2種類がある
– メモリベースには、ユーザーベースないしアイテムベースの二つのアプローチがある
– モデルベースのなかでも、行列分解はさまざまなかたちに応用され、今日のレコメンドの主要なアプローチの一つとなっている
・ ハイブリッド型のレコメンドは、協調フィルタリングをはじめ多様なアプローチを組み合わせて、欠点を補うことができる
・ レコメンドエンジンの選択においては、機能や性能を理解し、自社の課題解決に向けて戦略的な判断をすることが重要
【関連記事】
- レコメンドエンジンの仕組みと効果|顧客体験を向上させる最新活用法
- ECサイトの顧客エンゲージメントとは?向上方法を徹底解説
- F2転換を上げるには?
- パーソナライゼーションとは? 概念と目的を理解し、具体的な手法を知る
- ECにおけるロングテール戦略の基本とニッチな商品を活かす方法、成功事例
▼AI搭載レコメンドエンジンの機能について詳しく知るにはこちら!▼

* Netflixは、Netflix, Inc.の登録商標です。
AMAZONは、Amazon Services LLCおよびその関連会社の商標です。
Xeroxは米国ゼロックス社の登録商標または商標です。
本Webページに掲載されているその他の商品またはサービスなどの名称は、各社の商標または登録商標です。
** ” Recommended for you: Role, impact of tools behind automated product picks explored: Pros, cons of recommender systems” (https://www.sciencedaily.com/releases/2021/03/210304145157.htm), Science Daily, March 4, 2021
